本篇概述:第二篇的续作,主要是各种图片类型的下载和文件夹创建;
github地址、文中代码不一定能直接执行,粘贴过来可能缩进有问题。

1、分析——如何判断类型?
单图 ↓
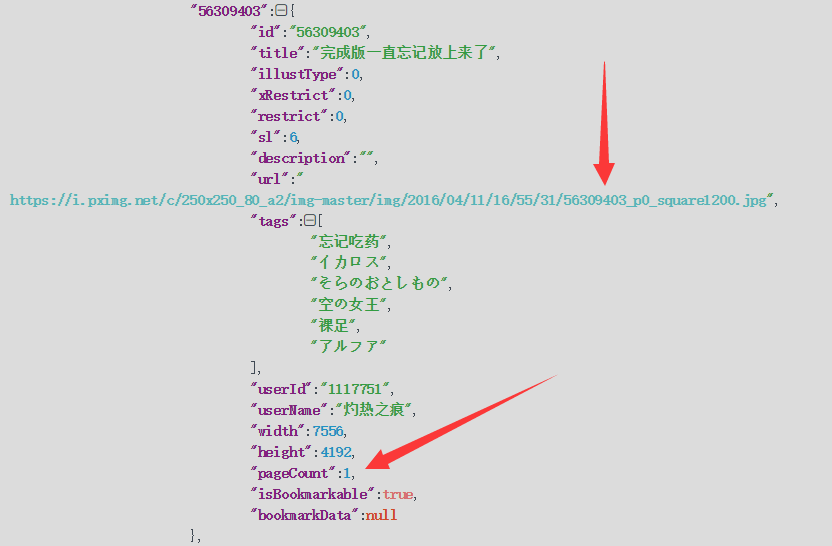
多图 ↓
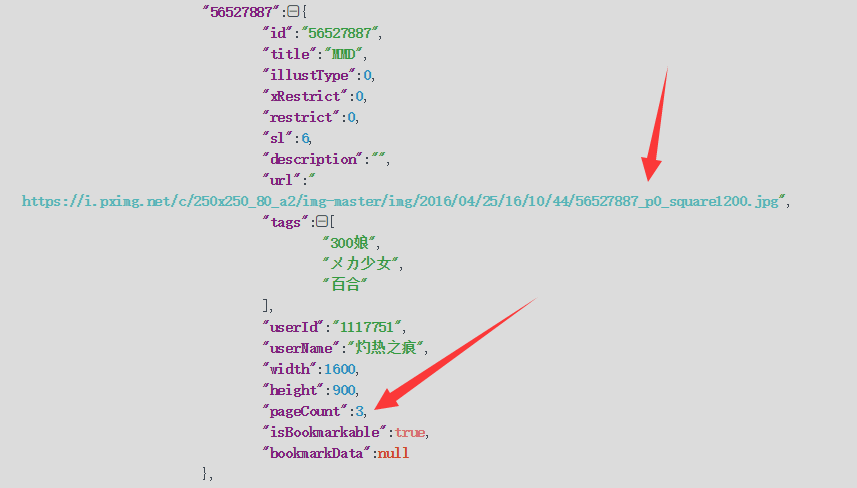
动图

仔细观察就会发现:
- 单图 url : 56309403_p0_square1200.jpg,有p0;pageCount:1
- 多图 url : 56527887_p0_square1200.jpg,有p0;pageCount:3
- 动图 url : 57027347_square1200.jpg,无p0;pageCount:1
2、代码——匹配类型
1 | def painter_picture(self): |
PS:拼接 url 时不要问为啥这么麻烦,看这里
- 本篇记录的是自己刚学python爬虫第一个爬虫项目的代码,这篇的代码可以说是仅仅是为了实现功能写出来的。
- 现在也有想法要重构,重构好之后发篇完整的出来,不过没有那么快而已。
- 现在找到了作品的详细信息接口,后面再更新了,这里用的是之前的方法。
- 回首看自己2个月前的代码,一点都不优雅。o(╥﹏╥)o
3、分析——创建画师文件夹及作品文件夹
- 首先指定一个下载目录
- 下载目录下为每个画师创建一个文件夹,形如:{id}–{name}
- 画师文件夹下为每个作品创建一个文件夹,形如:{id}
4、代码——文件夹
1、创建画师文件夹
此处解决了画师更改名字,会导致该画师所有作品重下。
具体看代码吧,解释也挺麻烦的
1 | # 执行 mkdir_painter() 应在 attention_html() 的 painter_information 循环中 |
2、创建作品文件夹
1 | def mkdir_works(self,folder_id): |
5、单图下载
1 | def img_single(self,small_url,folder_path,folder_id): |
6、多图下载
1 | def img_multi(self,small_url,folder_path,folder_id,pageCount): |
7、动图
P站动图其实只是多个图片设置页面停留时间而已,所以需要我们手动合成。
1.在动图的源文件地址(是个 zip 文件),里面有关于每个图片的 delay (也就是页面停留时间)和图片文件。
2.下载 zip,解压,用 imageio 进行合成,指定合成 gif 的帧率为 delay 就行了
但是存在一个问题,有些动图的每个图片设置的页面停留时间不同,这就让人很难搞了
1 | import imageio |
8、最后
鸽了挺久的,觉得大部分东西代码和实践都说得清楚,毕竟不是教程贴ヽ(ー_ー)ノ
github地址、文中代码不一定能直接执行,复制粘贴的。