本篇概述:Xpath语法,lxml解析html

一、什么是Xpath?
- XPath 是 XML 路径语言,主要是在 XML 和 HTML 文档中查找我们想要的信息的语言。
- XML 和 HTML 一样也是标记语言,但是 XML 用来传输和存储数据,而 HTML 用来显示数据
二、Xpath工具
- Google:Xpath Helper
(Google 插件可到下载Crx4Chrom(英文)、插件网、Chrome插件网 下载)
- Firefox:Try Xpath
- 每个浏览器一般在应用中心或拓展里都可以下载
Xpath Helper 界面

三、Xpath语法
1、路径表达式语法、相对/绝对路径
| 表达式 | 路径表达式及描述 |
|---|---|
| 节点名称 | bookstore,选取 bookstore 下的所有子节点(标签) |
| / | /bookstore,从根节点下选取所有 bookstore 节点(子元素) |
| // | //bookstore,从全局节点中选择 bookstore 节点 |
| @ | //div[@price=‘a’],选择所有 price 属性为 a 的 div |
| . | ./input,选择当前节点下的 input |
2、谓语
html 节点中第一个节点为 1,第二个为 2(需要区分)
| 表达式 | 描述 |
|---|---|
| //ul/li[1] | 选择 ul 下的第一个 li |
| //ul/li[last()-0] | 选择 ul 下的最后一个 li |
| //ul/li[last()-1] | 选择 ul 下的倒数第二个 li |
| //ul/li[position()<4] | 选择 ul 下前面的 3 个子元素 |
| //ul/li[position()>1] | 选择第二个到最后的所有子元素 |
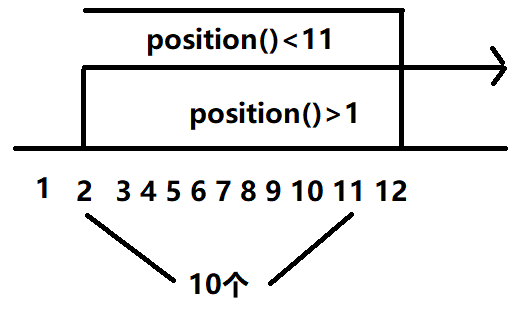
| //li[position()>1] [position()<11] | 在(2,+∞)中选择前十个 |
| text() | 获取函数文本 |
| @class | 获取标签的class |
通配符
| * | /bookstore/*,通配符,匹配 bookstore 下的所有子元素 |
|---|---|
| @* | //div[@*],选择所有带有属性的 div |
运算符
- “|“ —> //title | //ul[@class=‘item_con_list’],选择 title 和对应的 ul
四、使用lxml&xpath解析html
1 | html1 = etree.parse(index.html) # 可以通过读取html文件的方式 |
五、Example
- 以腾讯招聘网为例
- 我们要获取到职位名称、职位类别、人数、地点和发布时间等内容
- 2019.08.23 网站已变化
1 | //table//tr |
选择到了13个子元素,分别是表头,翻页和底部其他招聘
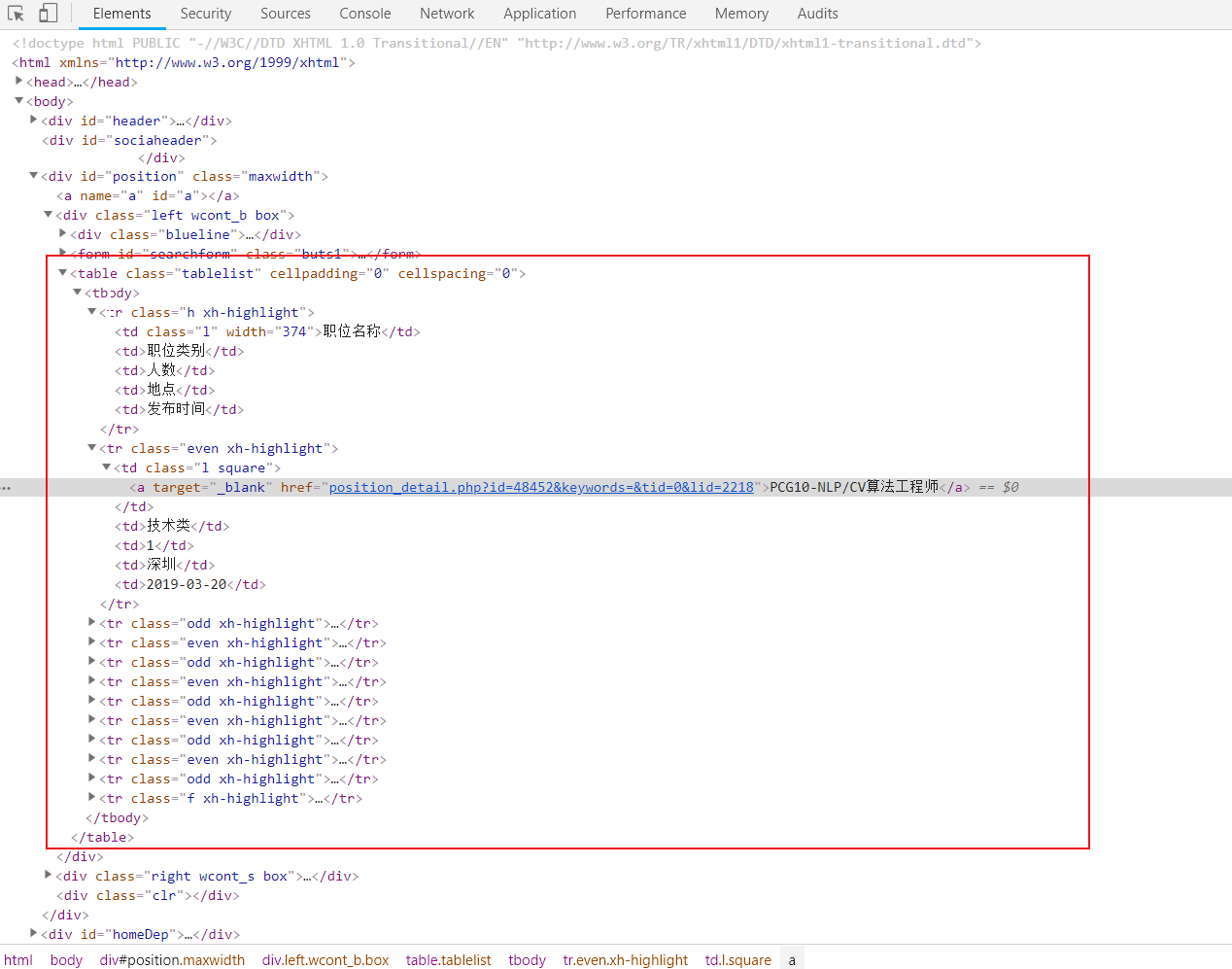
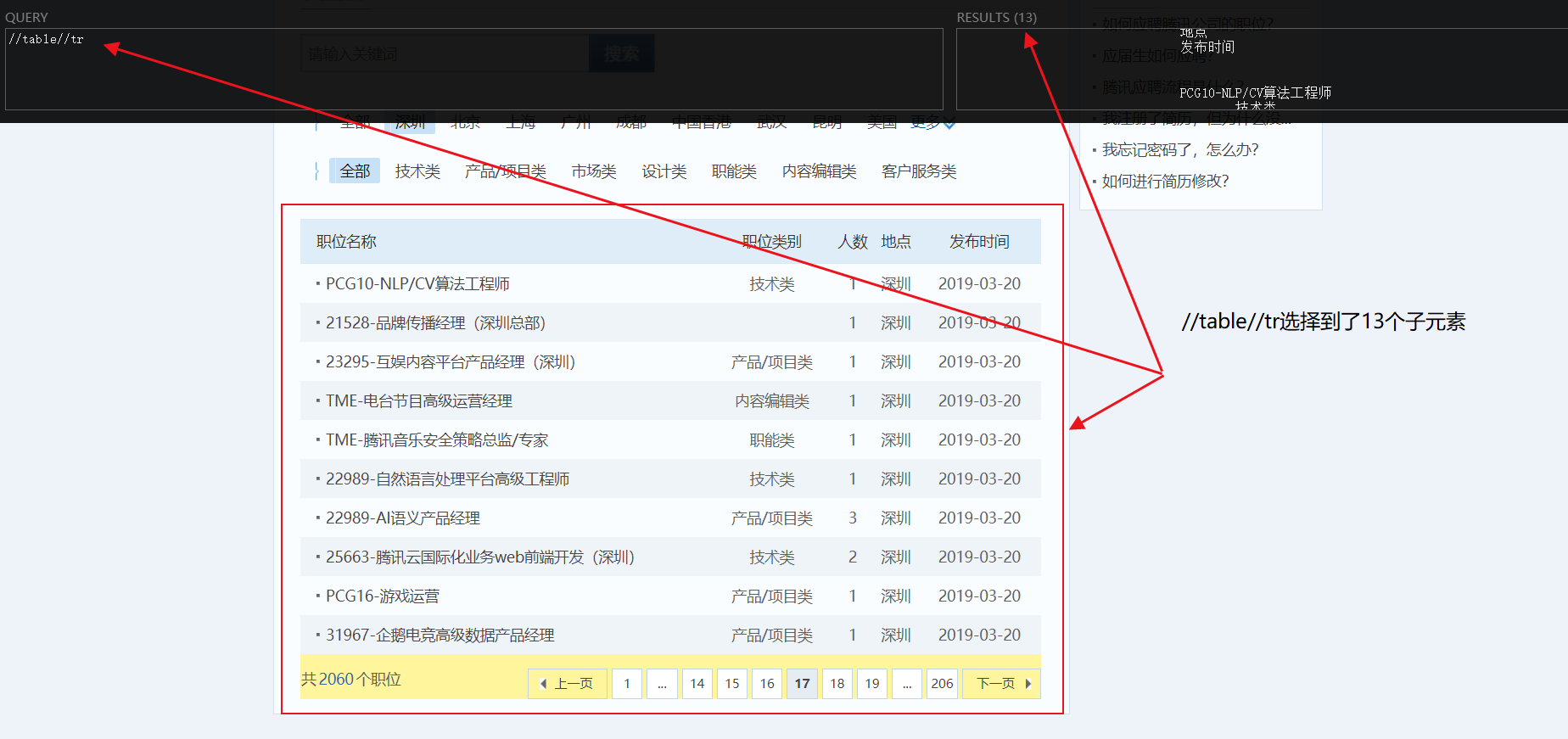
- 那么可以往上找父元素,扩大范围
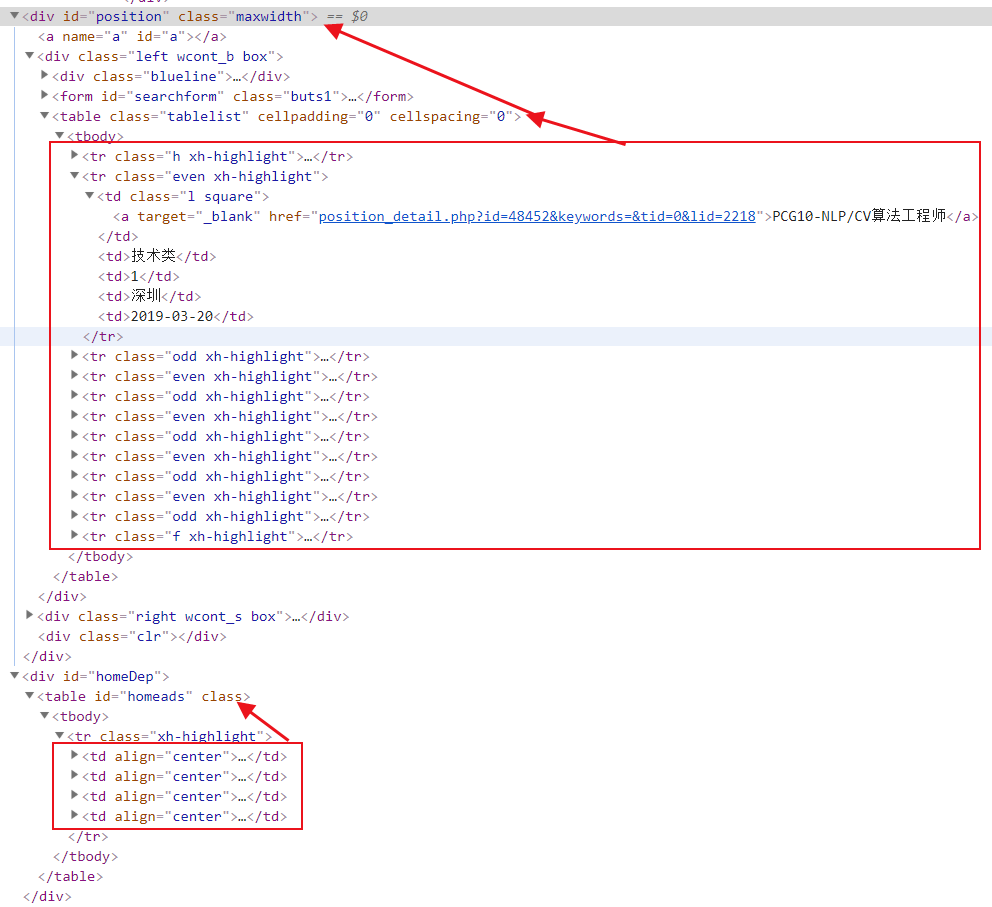
1 | //table[@class='tablelist']//tr[@class='even'] | //table[@class='tablelist']//tr[@class='odd'] |
- 使用以上表达式,避开表头和翻页
- 上述表达式虽然精确但是有点冗长,鉴于网站规律性,可以采用以下表达式
1 | //table[@class='tablelist']//tr[position()>1][position()<11] |
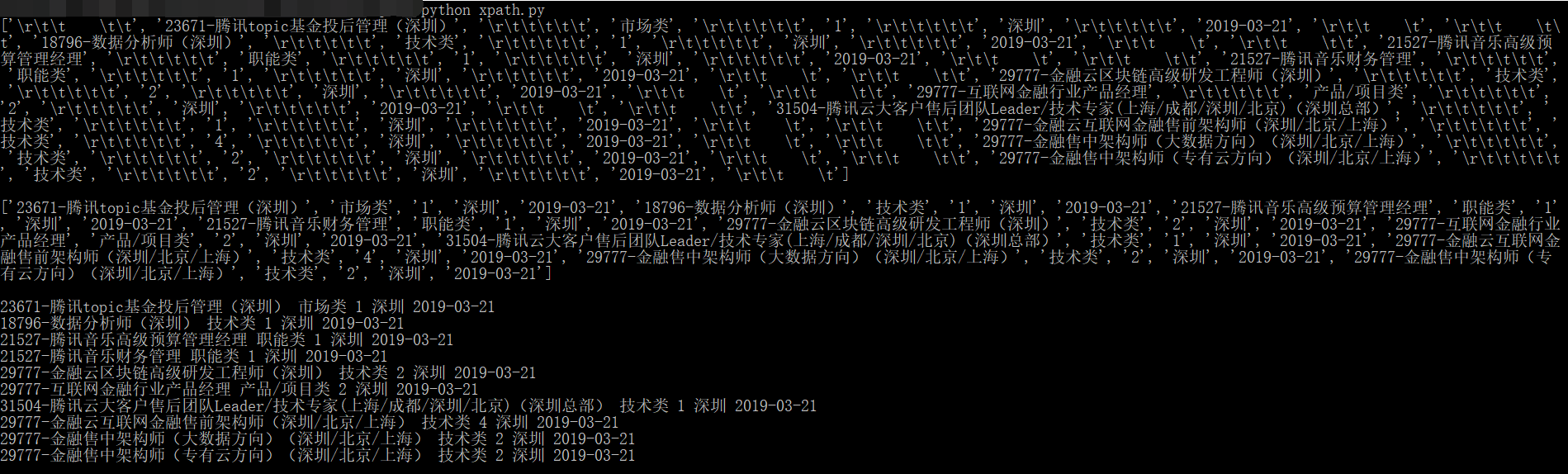
- 上面的表达式写在程序里不加text()来取的话,会返回类似
的结果。
1 | from lxml import etree |
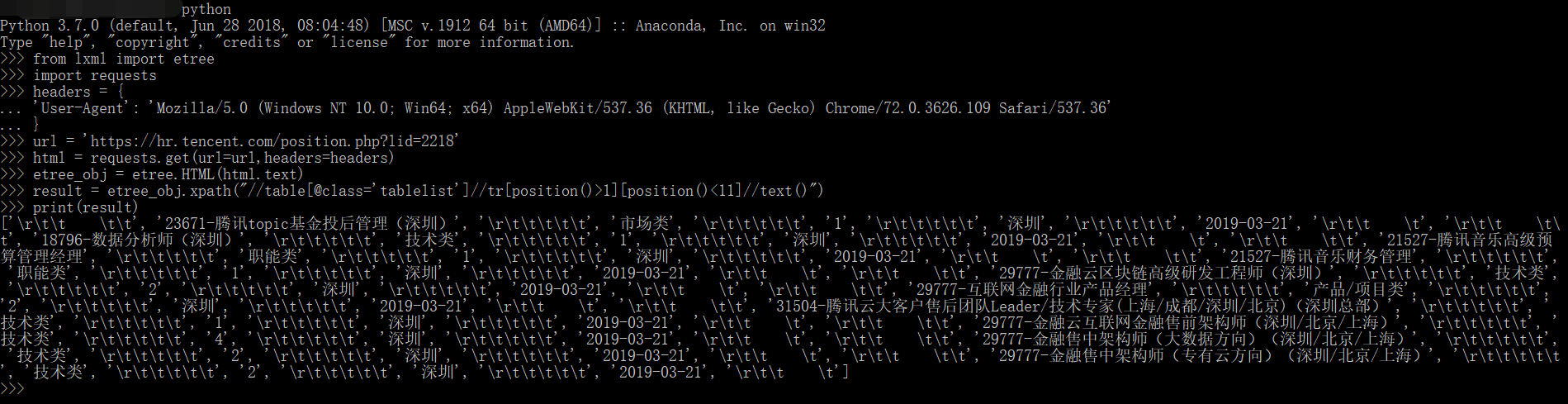
结果可以看到有许多的转义字符,比如:\r、\t
最后将代码处理一下,照此方法可以获取到腾讯招聘的所有职位信息(后面有个坑,比如职位类别是空数据的话,XPath匹配到会自动放弃)
1 | from lxml import etree |
- 结果图