本篇概述:代理原理作用,requests设置代理方法以及爬取免费代理的脚本实例

一、代理原理
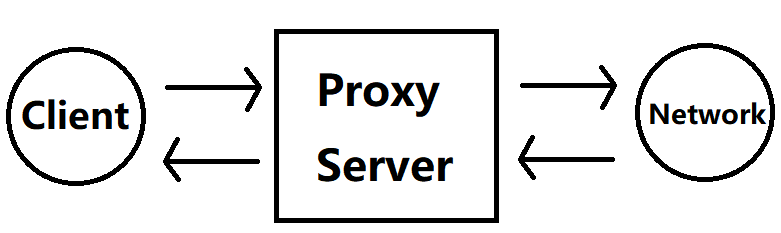
根据自己理解解读:
- 客户端设置了代理信息后,客户端向对应的代理站点发出请求(向xxx网站发起请求)
- 代理站点收到请求之后,就会执行对应的响应动作(执行动作)
- 代理站点获得xxx网站的响应(得到站点响应)
- 代理站点根据客户端要求返回对应信息(客户端要求返回Source code,则返回Source code)
二、代理作用
- 突破自身ip访问限制,比如访问国外站点
- 爬取对ip访问频率有一定限制的站点
- 提高访问速度
- 隐藏真实ip
三、代理网站
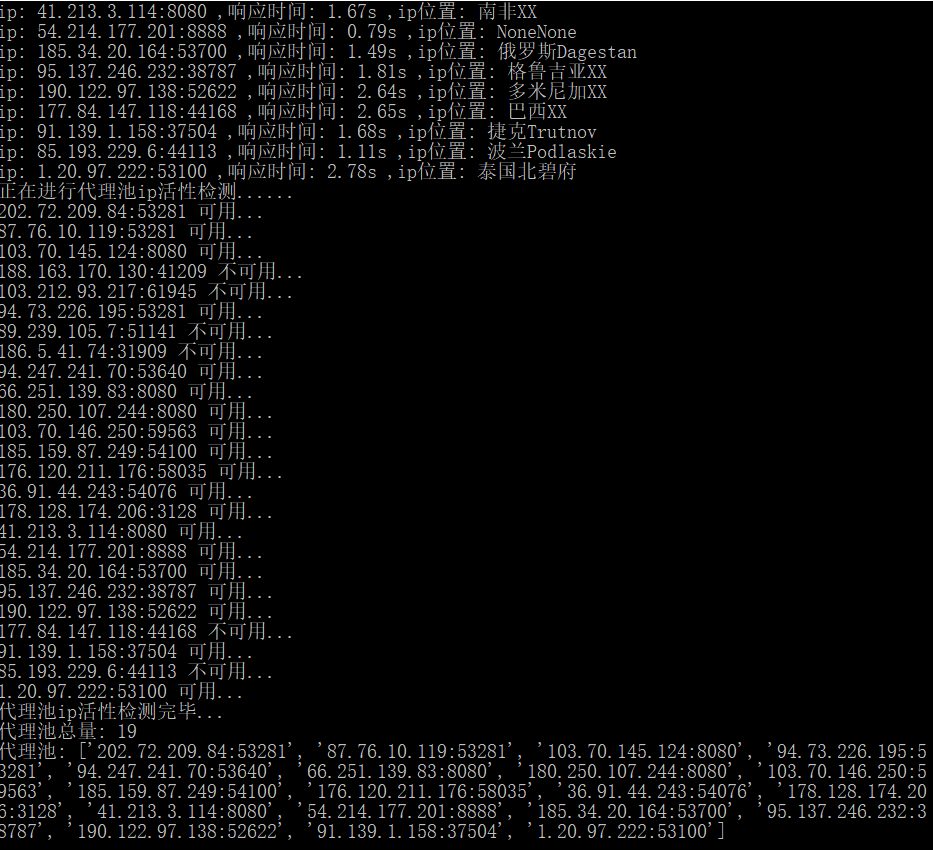
免费代理ip列表:
| 含国外ip | 方法SEO顾问,89代理,小幻http代理,云代理 |
|---|---|
| 不含 | 西刺,快代理 |
付费代理尚未了解,此处留空
四、requests设置代理方法
requests中有预设好的参数接收代理信息 proxies,这个参数接收的是一个字典对象
因为不知道访问的网站使用的是http协议还是https协议,所以proxies最好2种都有设置
1 | proxies = { |
五、脚本示例
github地址:https://github.com/Coder-Sakura/exp/tree/master/seo_ip
本来我是打算用89代理的api接口,但是测试之后发现可靠性有点低,并且外网ip比较少,所以转用SEO
(本次抓取代理ip主要是用在我自己做 pixiv 的小项目上,爬取关注画师的所有作品和自己的收藏作品,后续会整理出来,初学爬虫,有错还请指正)
1 | import requests |
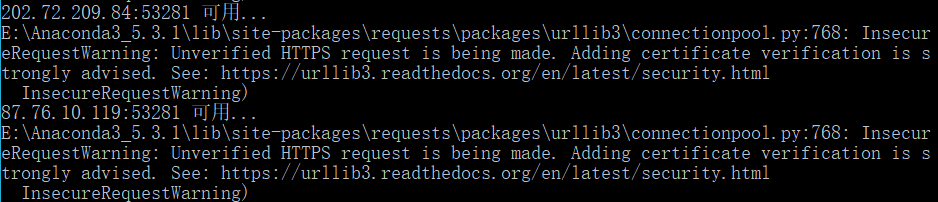
没有导入这2个库的话,会因为ssl证书而出现警告,如图:
- from requests.packages.urllib3.exceptions import InsecureRequestWarning
- from requests.adapters import HTTPAdapter
六、附图
最后附上运行图