本篇概述:本文主要解决爬虫登录pixiv问题。8月份 pixiv 添加 recaptcha_v3(Google V3版本验证)
1、Google V3验证?
何为 Google 验证码(reCAPTCHA v3)?
reCAPTCHA v3 会以嵌入js的方式,给网站后台返回一个分数,这个分数是用于判断用户是否是机器人,分数的范围是0~1,分数约接近0,越像机器人;
2、使用之前文章中的代码模拟登录 Pixiv
结果
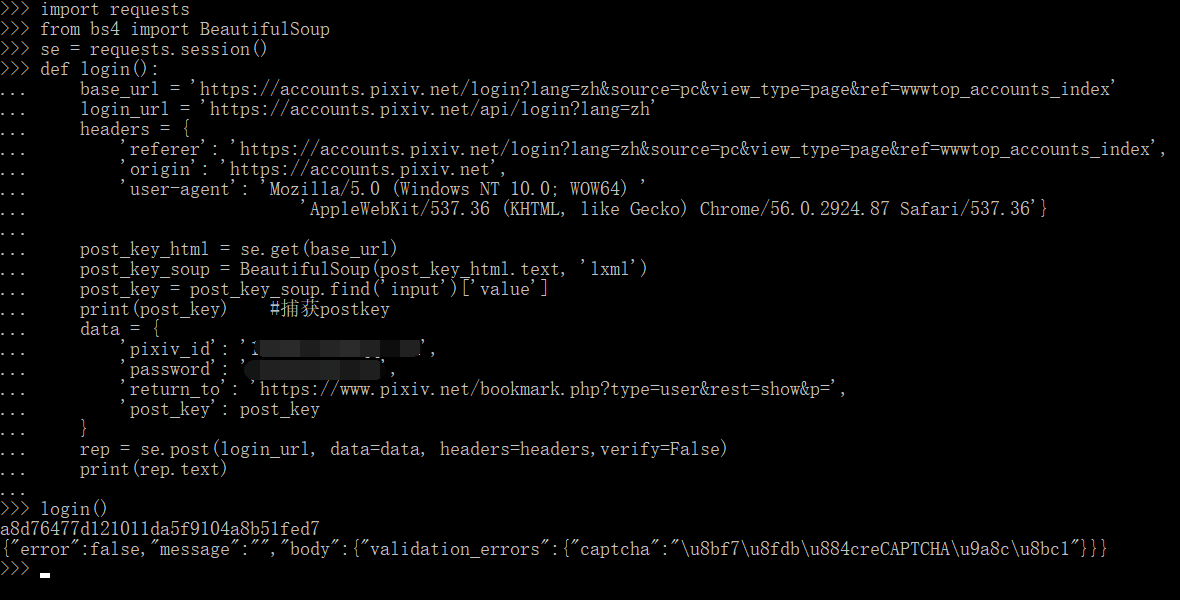
json 数据格式化一下 ↓

3、分析
我反复登录了几次,网页上并发现没有出现上图的 “I’m not a robot”
但是在登录抓包却看到 recaptcha_v3_token的值不为空,以前这个字段我记得是空的。
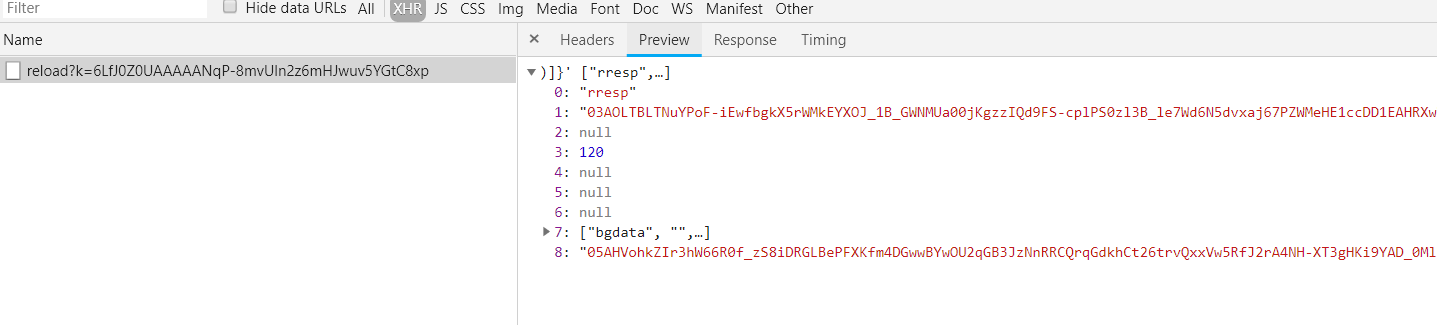
打开登录页面,f12打开调试工具–Network,点击XHR分页,可以看到每隔一段时间,通过 reload 重新请求一个 recaptcha_v3_token
(稍微等待一下,一会儿就会看到第二个reload出来了) ↓
登录的 from data,这个 recaptcha_v3_token ↓
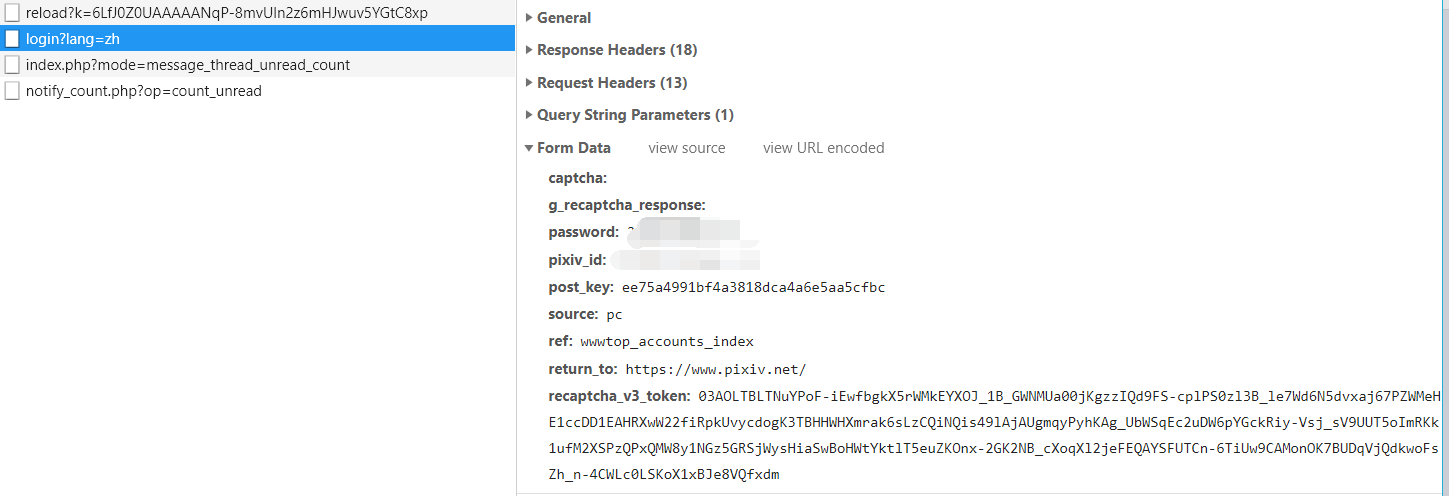
截个图,看看请求 recaptcha_v3_token 要 post 的字段 ↓
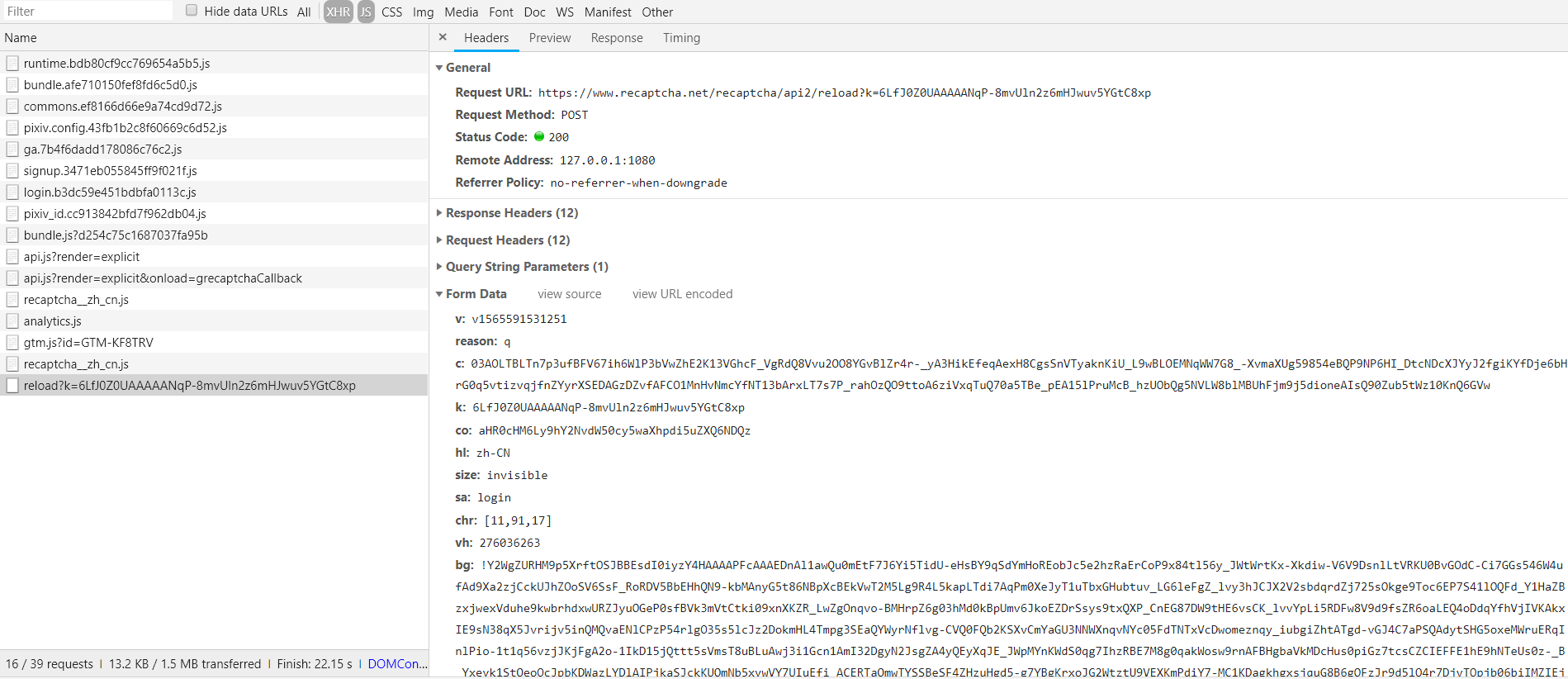

4、解决方案
1、手动抓包,在 headers 加入cookie 字段
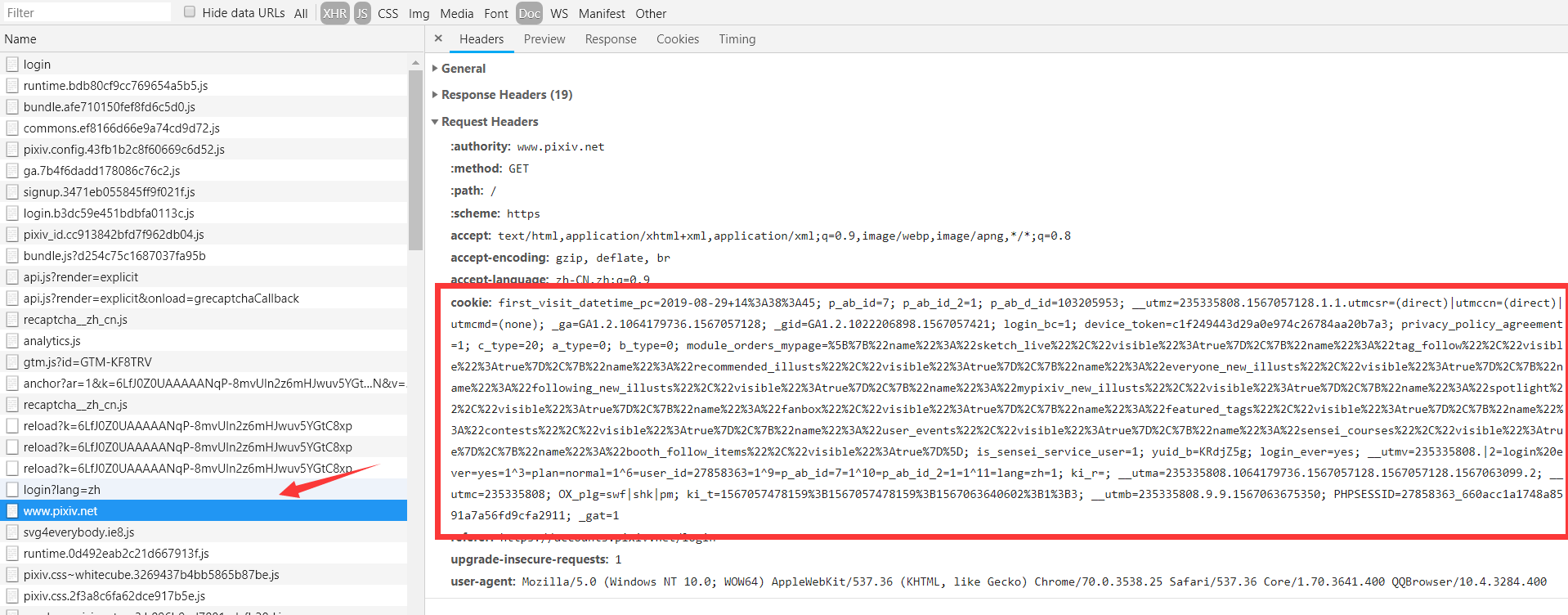
图太长,手动省略 ↓

2、selenium 抓取 (略)
个人比较喜欢用纯代码实现,虽然 selenium 也是要写代码。

3、selenium + requests (正文)
[Warning]:该方法食用前,请先确保手动在 Chrome 上登录 pixiv
selenium 自动保存 cookies
requests 读取 cookies 并维持会话
1 | from selenium import webdriver |
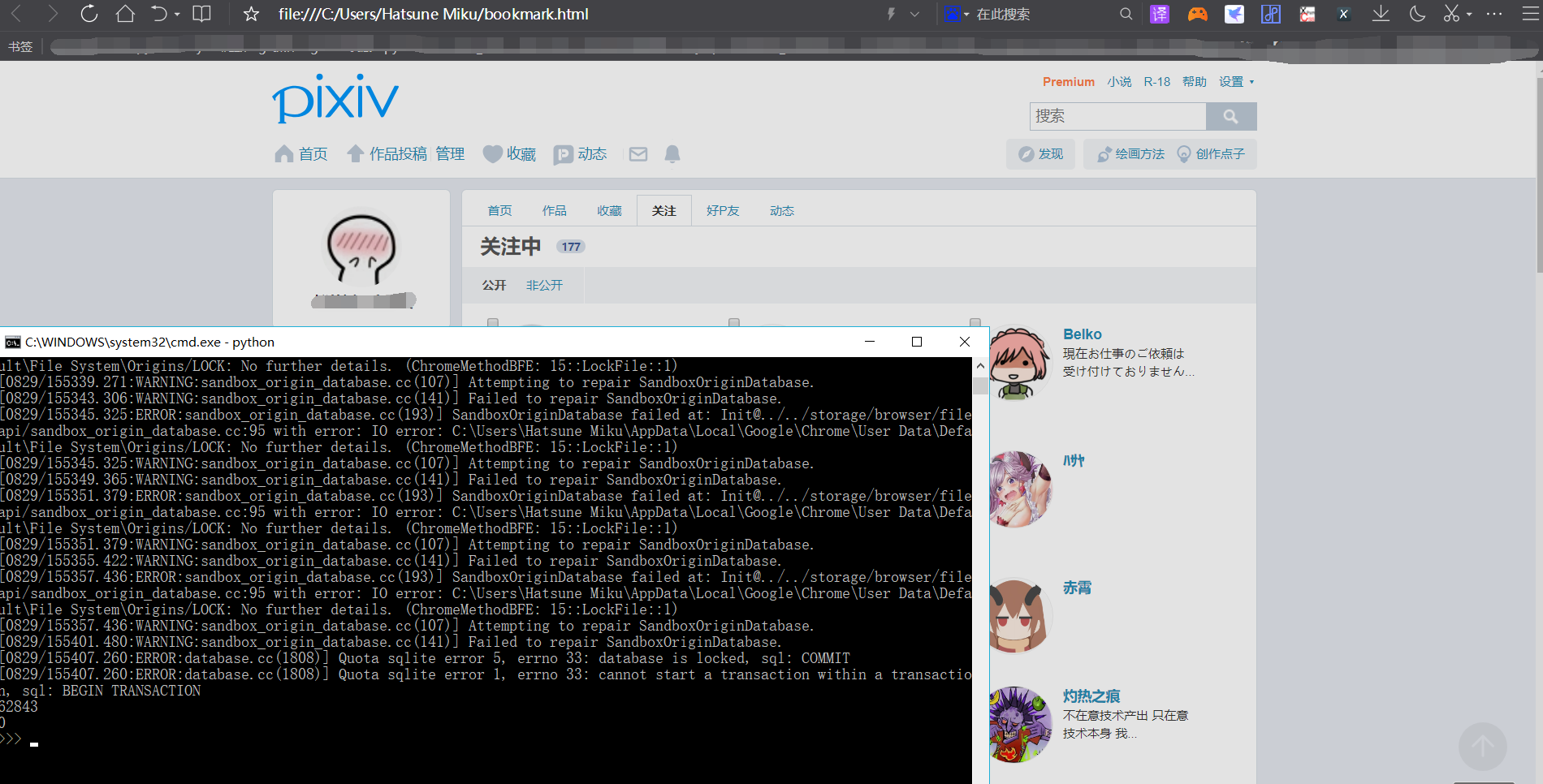
结果展示
代码运行结束,会打开一个个人关注画师网页(selenium运行中的警报再想办法处理了)
可以将上面代码稍作修改,然后再封装成一个获取 cookies 对象的函数,后面直接携带这个 cookies 就行了
剩下的,想要拿收藏的插画√、关注的画师√、排行榜插画√ 都是可以的。